Modèle composite conceptuel de données d'entreprise (CEDM)
McKinsey identifie l'ontologie comme un élément clé de la stratégie de données — la définition formelle des concepts d'affaires et de leurs relations. Notre MCDE composite répond précisément à ce besoin, avec une taxonomie de Sujets de données fournissant la structure composable à travers laquelle l'ontologie est organisée et navigable.
La modélisation de données d'entreprise est rare. La pratiquer avec rigueur, à grande échelle, dans plusieurs industries, sur plusieurs décennies — l'est encore plus. Le MCDE composite que nous construisons représente le savoir accumulé de quarante ans de pratique en architecture de données d'entreprise, désormais formalisé dans un tout nouveau cadre réutilisable et composable, conçu pour accélérer l'architecture de données gouvernée à travers les industries.
Ce qui le rend composite
Plutôt que de construire un modèle monolithique pour chaque industrie à partir de zéro, nous avons conçu une taxonomie de Sujets de données organisée en trois couches de réutilisabilité :
- Sujets de données communs — concepts universels applicables à toutes les industries et entreprises
- Sujets de données partagés — concepts partagés entre un sous-ensemble d'industries (comme les réservations, utilisées dans les industries du voyage, de l'hôtellerie et du divertissement en direct)
- Sujets de données spécifiques — concepts propres à une industrie ou à un contexte d'entreprise particulier
Un MCDE composite pour une industrie ou une entreprise donnée est assemblé en sélectionnant les Sujets de données appropriés de chaque couche — combinant des fondations universelles avec une précision propre à l'industrie. C'est notre propriété intellectuelle fondamentale, développée, raffinée et repensée à travers 15 industries sur quatre décennies.
L'architecture des Sujets de données (Taxonomie)
Les Sujets de données sont organisés de manière hiérarchique. Au Niveau 0, nous avons défini 22 Sujets de données communs qui forment le socle universel de tout modèle de données d'entreprise. Chaque Sujet de données de Niveau 0 contient des Sujets de données de Niveau 1 (N1), qui contiennent à leur tour des Sujets de données de Niveau 2 (N2). C'est au Niveau 2 que résident les entités réelles et leurs relations.
Voici quelques Sujets de données N1 faisant partie des 22 Sujets de données au Niveau 0 des Sujets de données communs.

Et voici quelques Sujets de données de Niveau 2 (N2) pour le Sujet de données N1 — Actifs physiques.

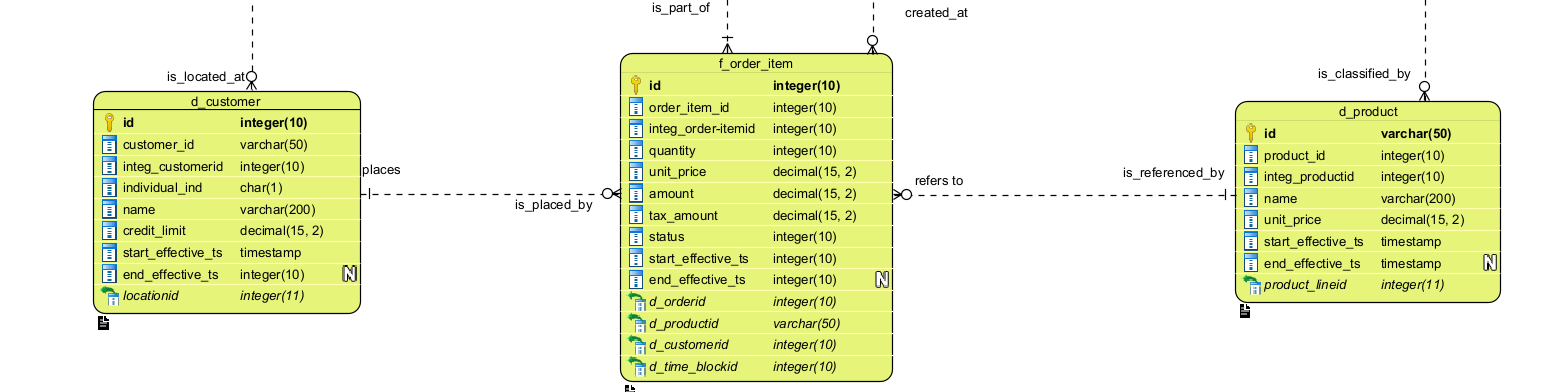
Le contenu de chaque Sujet de données N2 est un ensemble d'entités entièrement attribuées, typées, et de leurs relations. Ci-dessous se trouve une portion du modèle MCDE simplifié utilisé pour l'application de référence order_system_eda, composante de la Plateforme EDA. Dans le MCDE complet, Client, Commande et Produit résideraient chacun dans leurs Sujets de données N2 respectifs.
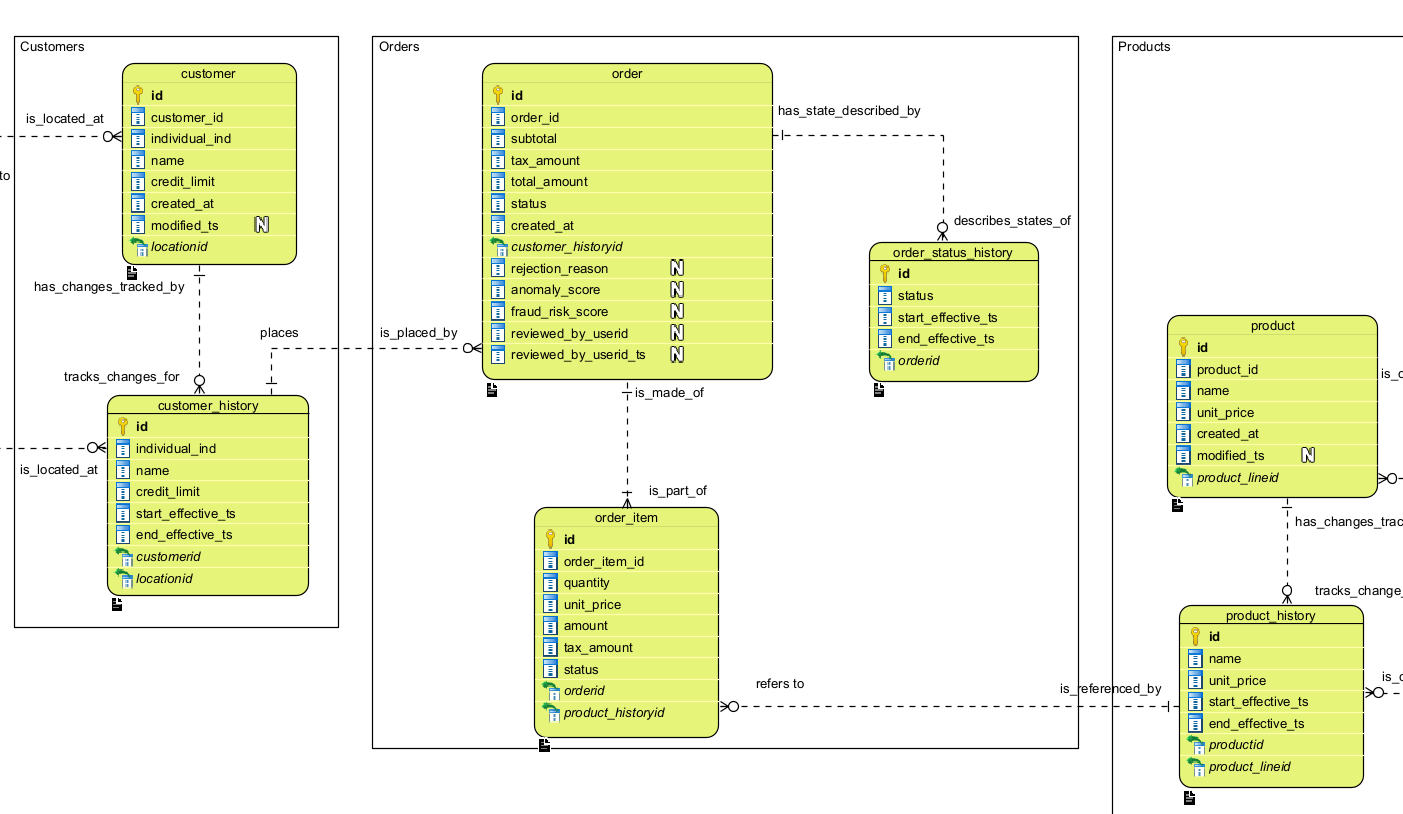
Chaque entité est entièrement attribuée et typée — car ce modèle exact sert de définition de gouvernance pour la zone d'intégration (couche Argent) du Lakehouse. Le MCDE n'est pas une documentation produite après coup ; c'est la source faisant autorité à partir de laquelle l'implémentation physique est dérivée.
Trois principes guident chaque décision de conception :
- Centré sur les affaires — chaque concept est défini d'un point de vue d'affaires, jamais d'un point de vue technique ou système
- Normalisé — la redondance est éliminée par conception, et non gérée après coup
- Capteur de changement — les entités telles que customer_history et product_history sont des citoyens de première classe du modèle, et non des ajouts secondaires
Cela contraste délibérément avec les bases de données applicatives, où les pressions de coûts, les délais de livraison et la dette technique accumulée — souvent héritée de logiciels progiciels ou de solutions SaaS — produisent des conceptions qui servent l'application, et non l'entreprise.
La zone d'intégration du Lakehouse doit implémenter le MCDE tel quel. C'est le contrat de gouvernance qui rend les données fiables à travers l'entreprise — et c'est ce qui distingue un Lakehouse gouverné d'un marécage de données.
Modèle dimensionnel de données d'entreprise (MDDE)
Le MDDE est le pendant analytique du MCDE — une réorganisation logique des concepts d'affaires destinée à la consommation par la BI, l'IA et la recherche opérationnelle. Il ne remplace pas le MCDE ; il l'étend vers la couche dimensionnelle, en préservant l'intégrité sémantique tout en optimisant pour la requête et l'analyse.
Comme le MCDE, le MDDE est organisé sous forme de taxonomie où chaque dimension appartient à un progiciel spécifique, le rendant composable et navigable à travers les industries.
Au-delà du schéma en étoile — Le flocon de neige dénormalisé
L'industrie débat depuis longtemps du schéma en étoile versus le schéma en flocon de neige. Les schémas en étoile sont efficaces pour les requêtes mais sémantiquement pauvres — les dimensions sont aplaties, les points d'ancrage sont perdus, et les tables de faits sont couramment associées à des dates arbitraires plutôt qu'à des périodes d'affaires significatives. Une statistique mensuelle d'Industrie Canada devrait s'ancrer à un mois, non à un jour arbitraire fabriqué pour s'adapter à une dimension de date.
Les schémas en flocon de neige préservent la normalisation et la précision sémantique, mais introduisent des jointures à plusieurs niveaux qui dégradent les performances des requêtes — un coût réel à l'échelle de l'entreprise.
Le flocon de neige dénormalisé a été conçu et implémenté pour la première fois par Richard Langlois il y a plus de vingt ans et a depuis été déployé dans plusieurs entreprises canadiennes couvrant les services financiers, le commerce de détail, la distribution, les télécommunications et les médias. Il résout la tension étoile/flocon de neige avec un schéma en flocon où des colonnes dénormalisées sont propagées à travers tous les niveaux de chaque dimension — offrant systématiquement les performances d'un schéma en étoile avec l'intégrité sémantique et la précision analytique que les schémas en étoile ne peuvent pas fournir. Le résultat :
- Efficacité des jointures égale à un schéma en étoile — la jointure de table de faits est aussi performante qu'une étoile
- Points d'ancrage valides préservés — chaque niveau de dimension est un concept d'affaires significatif, non un artefact technique
- Navigation OLAP supérieure — les requêtes traversent uniquement les niveaux dimensionnels nécessaires, lisant moins de données qu'un schéma en étoile tout en maintenant toute la richesse sémantique
- Ancrage naturel des métadonnées BI — PowerBI, Tableau et autres outils peuvent définir des hiérarchies contre de véritables niveaux d'affaires, guidés par la structure du MDDE plutôt qu'improvisés par des développeurs BI individuels
Chaque table de faits est modélisée dans son propre progiciel, avec toutes les relations dimensionnelles affichées à leurs points d'ancrage corrects — rendant le modèle analytique aussi centré sur les affaires que le MCDE lui-même. Cela contraste fortement avec les schémas en étoile, qui sont fréquemment sous-conçus et laissent les décisions sémantiques aux équipes BI en aval, qui n'ont pas le contexte d'architecture de données d'entreprise pour les prendre correctement.
Ci-dessous se trouve un extrait du modèle MDDE utilisé dans la zone Or de la Plateforme Lakehouse — encore une fois une portée réduite reflétant l'architecture de référence opérationnelle. Comme pour le MCDE, la taxonomie complète de l'industrie n'a pas été appliquée ici.