McKinsey identifies ontology as a key element of data strategy — the formal definition of business concepts and their relationships. Our composite CEDM delivers precisely that, with a taxonomy of Data Subjects providing the composable structure through which the ontology is organized and navigated
Enterprise data modeling is rare. Doing it well, at scale, across multiple industries, over decades — is rarer still. The composite CEDM we are building represents the accumulated knowledge of forty years of enterprise data architecture practice, now formalized into a brand new reusable, composable framework designed to accelerate governed data architecture across industries.
What Makes It Composite
Rather than building a monolithic model for each industry from scratch, we designed a taxonomy of Data Subjects organized into three layers of reusability:
- Common Data Subjects — universal concepts that apply across all industries and enterprises
- Shared Data Subjects — concepts shared across a subset of industries (such as reservations which is used for travel, hospitality & live entertainment industries)
- Specific Data Subjects — concepts unique to a particular industry or enterprise context
A composite CEDM for any given industry or enterprise is assembled by selecting the appropriate Data Subjects from each layer — combining universal foundations with industry-specific precision. This is our core IP, developed, refined and redesigned across 15 industries over four decades.
The Architecture of Data Subjects (Taxonomy)
Data Subjects are organized hierarchically. At Level 0, we have defined 22 Common Data Subjects that form the universal foundation of any enterprise data model. Each Level 0 Data Subject contains Level 1 (L1) Data Subjects, which in turn contain Level 2 (L2) Data Subjects. L2 Data Subjects are where the actual entities and their relationships live.
Here are some L1 Data Subjects that are part of the 22 Data Subjects at Level 0 Common Data Subjects.

And here are some level 2 (L2) Data Subjects for the L1-Physical Assets Data Subjects.

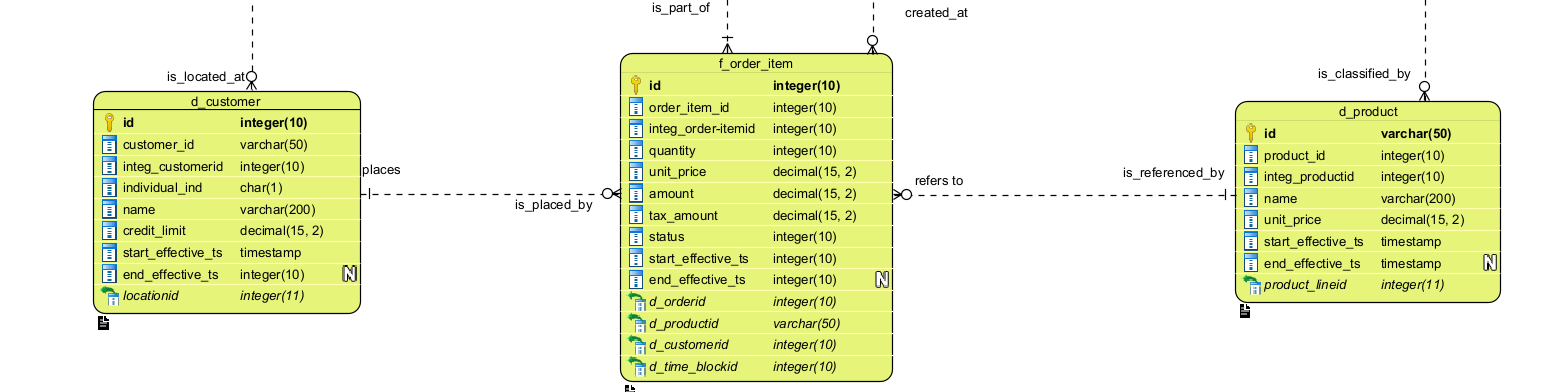
The content of each L2 Data Subject is a set of fully attributed, typed entities and their relationships. Below is a portion of the simplified CEDM model used for the order_system_eda reference application, part of the EDA Platform. In the full CEDM, Customer, Order, and Product would each reside in their respective L2 Data Subjects.
Every entity is fully attributed and typed — because this exact model serves as the governing definition for the integration zone (Silver layer) of the Lakehouse. The CEDM is not documentation produced after the fact; it is the authoritative source from which physical implementation is derived.
Three principles guide every design decision:
- Business-centric — every concept is defined from a business perspective, never from a technical or system perspective
- Normalized — redundancy is eliminated by design, not managed after the fact
- Change-capturing — entities such as customer_history and product_history are first-class model citizens, not afterthoughts
This stands in deliberate contrast to application databases, where cost pressures, delivery deadlines, and accumulated technical debt — often inherited from packaged software or SaaS solutions — produce designs that serve the application, not the enterprise.
The Lakehouse integration zone must implement the CEDM as-is. This is the governance contract that makes data trustworthy across the enterprise — and it is what separates a governed Lakehouse from a data swamp.
Dimensional Enterprise Data Model (DEDM)
The DEDM is the analytical counterpart to the CEDM — a logical reorganization of business concepts for consumption by BI, AI, and Operational Research. It does not replace the CEDM; it extends it into the dimensional layer, preserving semantic integrity while optimizing for query and analysis.
Like the CEDM, the DEDM is organized as a taxonomy where each dimension belongs to a specific package, making it composable and navigable across industries.
Beyond the Star Schema — The Denormalized Snowflake
The industry has long debated Star schema versus Snowflake. Star schemas are query-efficient but semantically poor — dimensions are collapsed, anchorage points are lost, and fact tables are routinely associated to arbitrary dates rather than meaningful business time periods. A monthly statistic from Industry Canada should anchor to a month, not an arbitrary day fabricated to fit a date dimension.
Snowflake schemas preserve normalization and semantic precision but introduce multi-level joins that degrade query performance — a real cost at enterprise scale.
The Denormalized Snowflake was conceived and first implemented by Richard Langlois over twenty years ago and has since been deployed across multiple Canadian enterprises spanning financial services, retail, distribution, telecom, and media. It resolves the Star vs. Snowflake tension with a snowflake schema where denormalized columns are propagated across all levels of each dimension — consistently delivering Star schema performance with the semantic integrity and analytical precision that Star schemas cannot provide. The result:
- Join efficiency equal to Star schema — the fact table join is as performant as a Star
- Valid anchorage points preserved — every dimension level is a meaningful business concept, not a technical artifact
- Superior OLAP navigation — queries traverse only the dimensional levels needed, reading less data than a Star schema while maintaining full semantic richness
- Natural BI metadata anchoring — PowerBI, Tableau, and other tools can define hierarchies against real business levels, guided by the DEDM structure rather than improvised by individual BI developers
Each fact table is modeled in its own package, with all dimensional relationships shown at their correct anchorage points — making the analytical model as business-centric as the CEDM itself. This stands in sharp contrast to Star schemas, which are frequently under-designed and leave semantic decisions to downstream BI teams who lack the enterprise data architecture context to make them correctly.
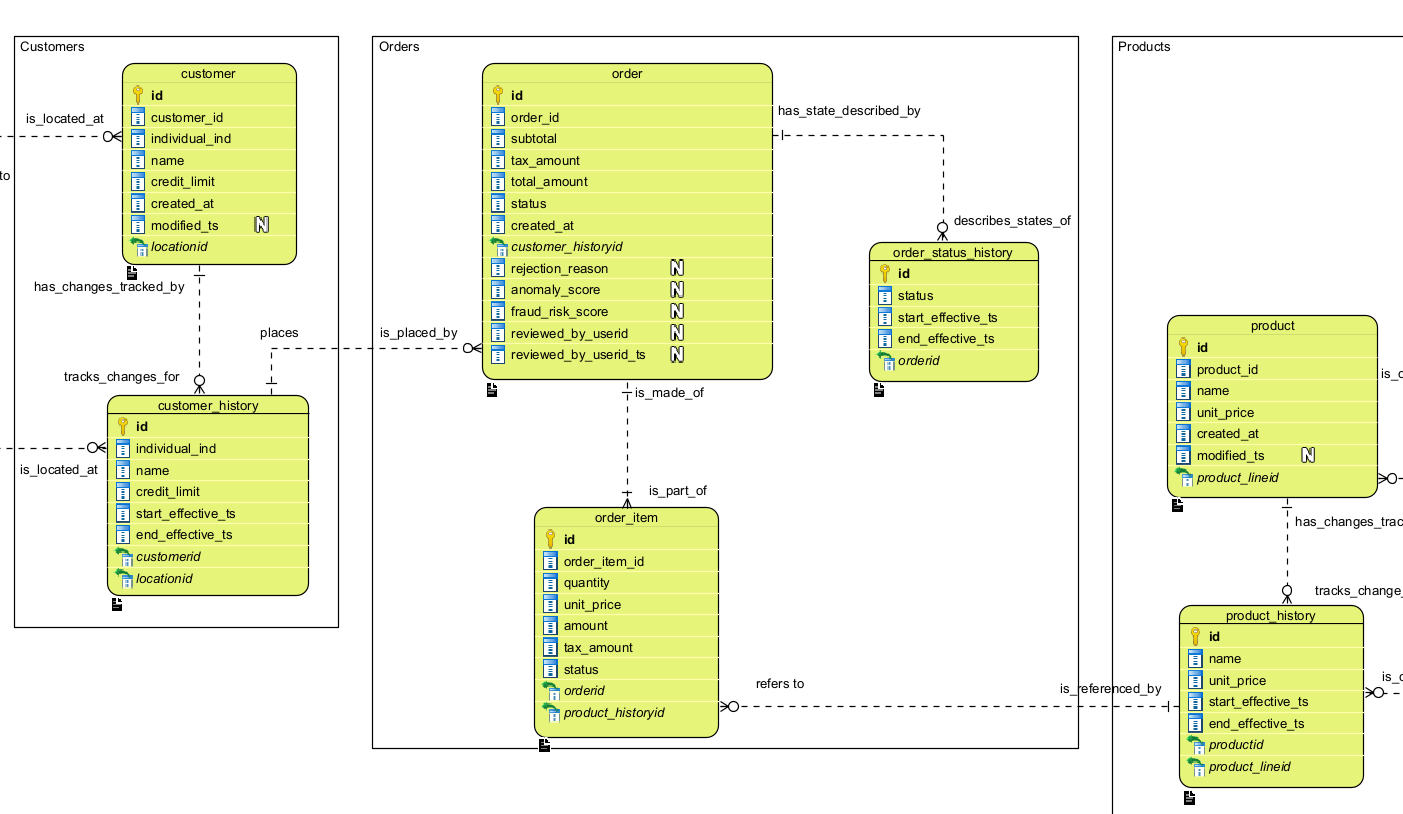
Below is an extract of the DEDM model used in the Gold zone of the Lakehouse Platform — again a reduced scope reflecting the working reference architecture. As with the CEDM, the full industry taxonomy has not been applied here